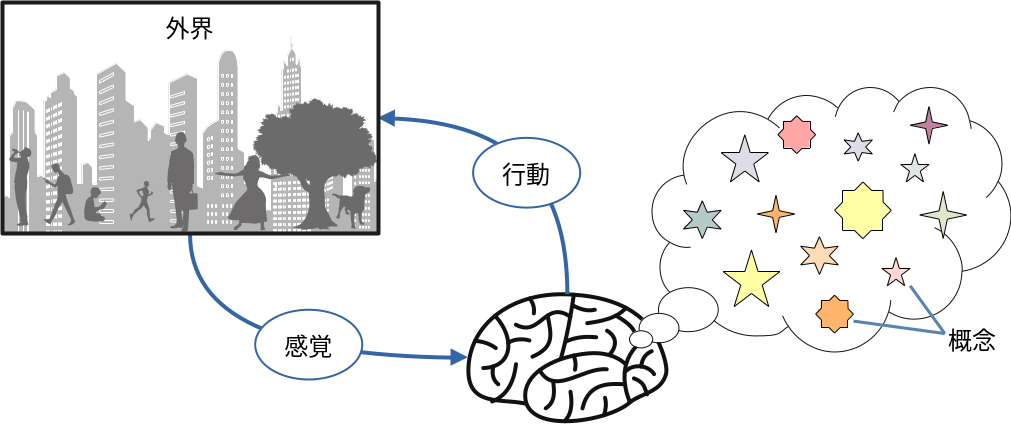
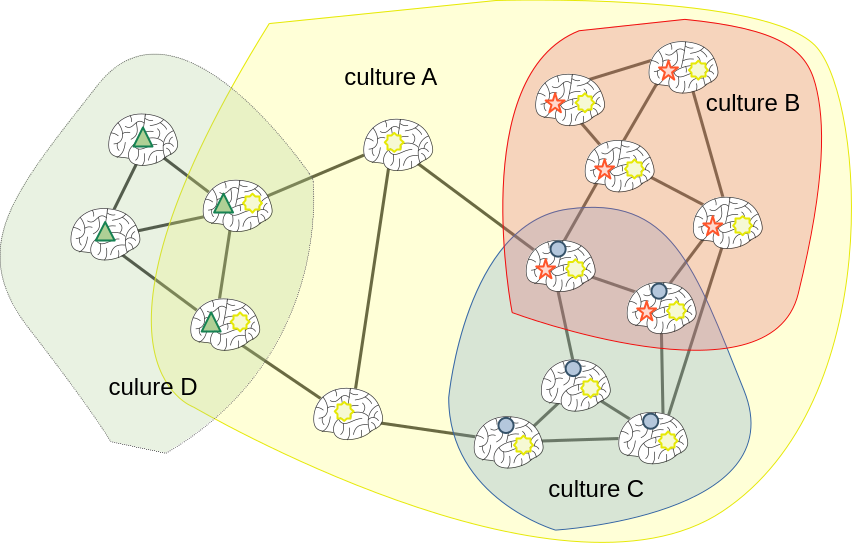
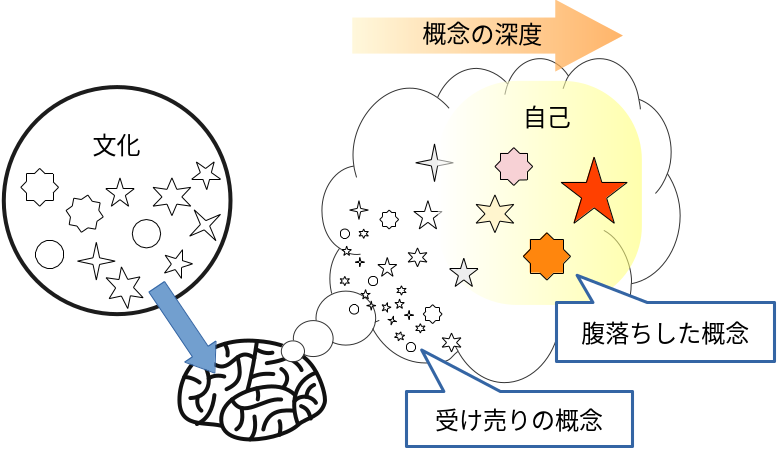
ジョン・T・ジョストは、人々が現行の社会システムを正当化してしまう欲求の研究をしています。彼によれば、私達は不安定で無秩序な状態を嫌うあまり、自分が気づいている以上に、自分の依って立つ社会の組織や仕組みをすぐ防衛したがると言います。彼の仮説には「現在の社会システムや権力機構を正当化しようとする最も強い欲求を持つ人たちは最も不利な立場に置かれている人たちである」というものまであり、その検証がなされています
John T. Jost et al. (2003) Social inequality and the reduction of ideological dissonance on behalf of the system: Evidence of enhanced system justification among the disadvantaged。これは自身を取り巻く環境によってあるべき行動が決まり、それを信じるための根拠を信じる例になります。
1930年、経済学者のジョン・メイナード・ケインズは"Economic Possibilities for our Grandchildren"の中で、技術進歩と資本の蓄積によって、あと100年くらいあれば経済問題の解決は可能であり、労働から解放された未来を予測しています。2024年現在、技術の進歩と資本の蓄積の予測は的中しましたが、残念ながら経済問題はより深刻になる一方で、あと6年で解決に向かいそうな気配はありません。
Will this be a benefit? If one believes at all in the real values of life, the prospect at least opens up the possibility of benefit. Yet I think with dread of the readjustment of the habits and instincts of the ordinary man, bred into him for countless generations, which he may be asked to discard within a few decades. これは有益なのだろうか? もし人生の真の価値を信じる者なら、恩恵がもたらされる可能性はあるように見通せるだろう。とはいえ、何世代にもわたって培われてきた習慣や本能を数十年のうちに捨て去ることが一般庶民に要求されることを想像すると私は恐怖を感じる。J.ケインズ “Economic Possibilities for our Grandchildren"より
a bullshit job is a form of paid employment that is so completely pointless, unnecessary, or pernicious that even the employee cannot justify its existence even though, as part of the conditions of employment, the employee feels obliged to pretend that this is not the case. ブルシットジョブとは、被雇用者本人でさえ、その存在を正当化しがたいほど、完璧に無意味で、不必要で、有害でさえある有償の雇用の形態である。とはいえ、その雇用条件の一環として、被雇用者は、そうではないととりつくろわねばならないと感じている。
While the system card itself has been well received among researchers interested in understanding GPT-4’s risk profile, it appears to have been less successful as a broader signal of OpenAI’s commitment to safety. The reason for this unintended outcome is that the company took other actions that overshadowed the import of the system card: most notably, the blockbuster release of ChatGPT four months earlier. (…) This result seems strikingly similar to the race-to-the-bottom dynamics that OpenAI and others have stated that they wish to avoid. OpenAI has also drawn criticism for many other safety and ethics issues related to the launches of ChatGPT and GPT-4, including regarding copyright issues, labor conditions for data annotators, and the susceptibility of their products to “jailbreaks” that allow users to bypass safety controls. システムカード自体は、GPT-4のリスク評価の理解に関心のある研究者の間では好評であったが、安全性に対するOpenAIのコミットメントを広く示すものとしては、あまり成功しなかったようである。この意図しない結果の理由は、同社がシステムカードの重要性を覆すような他の行動をとったからである。最も顕著なのは、ChatGPTのリリースを4ヶ月早めたことである。(略) この結果は、OpenAIや他社が避けたいと表明している「底辺への競争」に酷似しているように思われる。またOpenAIはChatGPTとGPT-4のリリースに関して、著作権問題、アノテーター学習データを作る人。第一章参照の労働条件、ユーザーが安全制御を回避することを可能にする「ジェイルブレイク」の影響を受けやすいことなど、その他多くの安全性と倫理に関する問題で批判を浴びている。
研究者の間で好評の「システムカード」とはAIのセキュリティについての12項目をOpenAIがまとめた文書です
2024.3.4 GPT-4 Technical Report Appendix H GPT-4 System Cardhttps://arxiv.org/pdf/2303.08774。また「底辺への競争」とは、競争のプレッシャーから製品やサービスの品質の競争ではなく安全性や倫理を軽視する競争に陥り、全体として底辺に向かっていくことを指します。OpenAIはリリースを早めたことで他の企業にプレッシャーを与え底辺への競争を招いていることなど、信頼できる企業姿勢を提示できていないことをトナーらは指摘しています。 トナーらは民主的なプロセスに基づいたAIの開発や普及の必要性を訴えます。しかし、その思想は人工生知能の群れの動きに合致しておらず、追従できなかった人々が振り落とされたようです。
The impact of GPT-4 on the economy and workforce should be a crucial consideration for policymakers and other stakeholders. GPT-4が経済や労働力に与えるインパクトは政策立案者やその他のステークホルダーにとって重大な検討事項です。